
Chung-Wei Lee
[Google Scholar]
lee@chungwei.net
I am a research scientist at Meta. Prior to that, I spent my time at WorldQuant conducting machine learning and artificial intelligence research in quantitative finance. I hold a PhD in Computer Science at the University of Southern California, where I was very fortunate to be advised by Prof. Haipeng Luo. My PhD research centers around the intersection of theoretical machine learning and algorithmic game theory. Specifically, I study fundamental sequential decision-making problems involving multiple agents in partially observable environments. Prior to pursuing my PhD, I received my B.S. from National Taiwan University, double majoring in Electrical Engineering and Mathematics. During that time, I had the privilege of working alongside Prof. Yu-Chiang Frank Wang on Computer Vision and Deep Learning projects.
I am honored and grateful to have been granted permanent residency in the U.S. (a green card) through the EB-1 category, which recognizes my extraordinary abilities and contributions to the field of AI. This opportunity enables me to continue my research and advance the frontiers of AI in the U.S.
Work Experience


Internship Experience



Publications
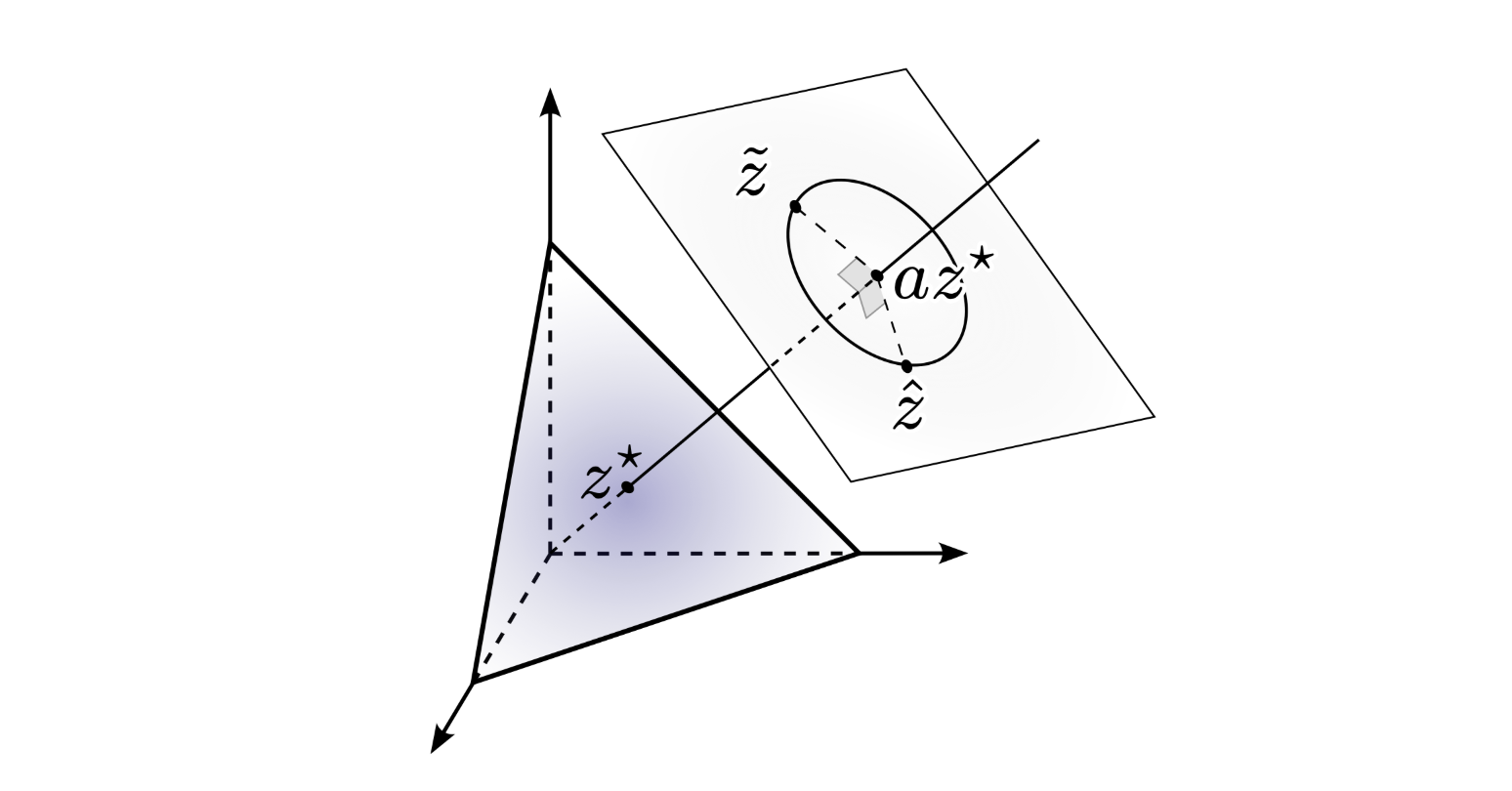
Last-Iterate Convergence Properties of Regret-Matching Algorithms in Games
(α-β order) Yang Cai, Gabriele Farina, Julien Grand-Clément, Christian Kroer, Chung-Wei Lee, Haipeng Luo, Weiqiang ZhengConference on Learning Representations (ICLR) 2025.
[arxiv]
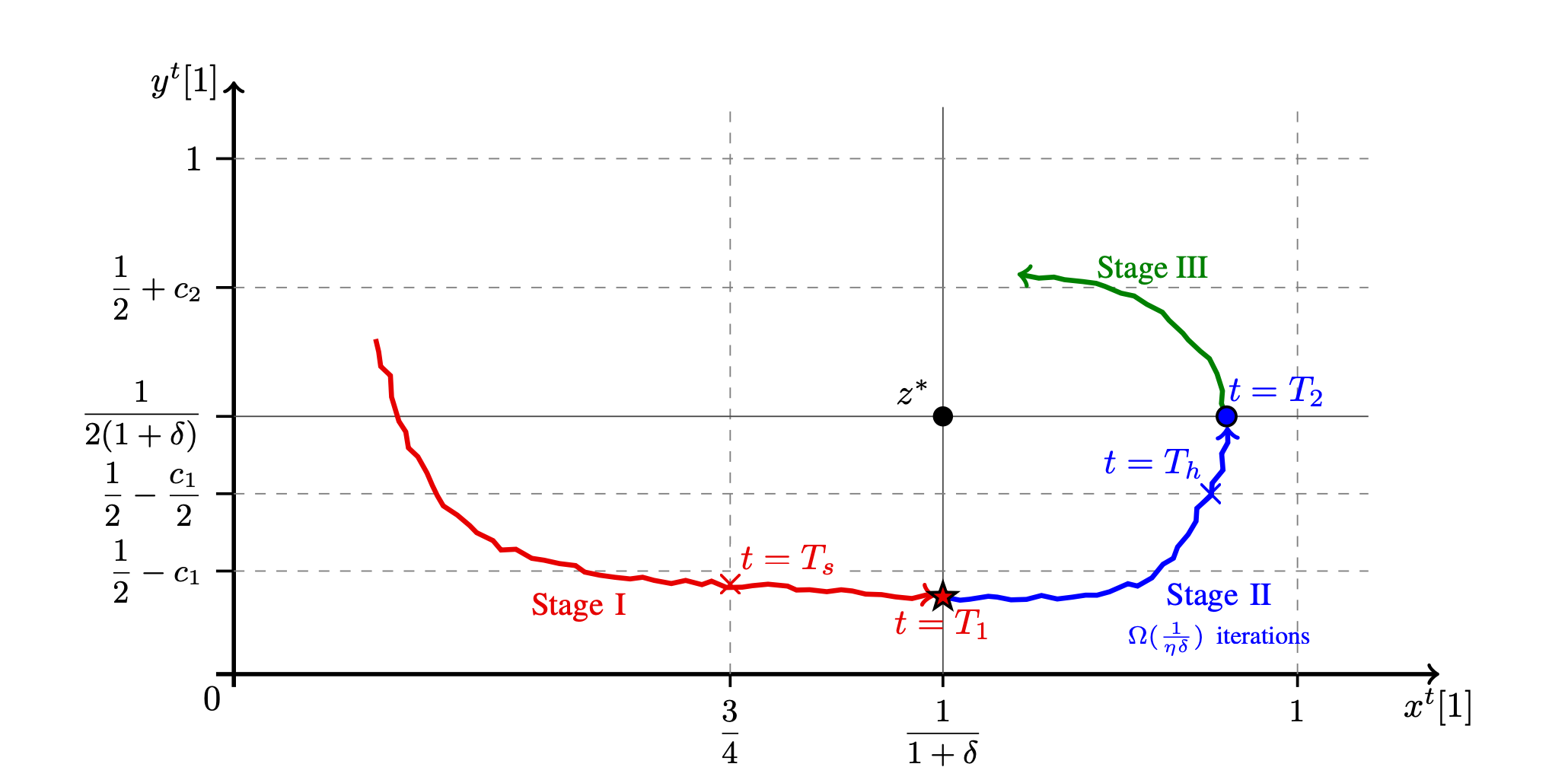
Fast Last-Iterate Convergence of Learning in Games Requires Forgetful Algorithms
(α-β order) Yang Cai, Gabriele Farina, Julien Grand-Clément, Christian Kroer, Chung-Wei Lee, Haipeng Luo, Weiqiang ZhengConference on Neural Information Processing Systems (NeurIPS) 2024.
[arxiv]

Context-lumpable Stochastic Bandits
Chung-Wei Lee, Qinghua Liu, Yasin Abbasi-Yadkori, Chi Jin, Tor Lattimore, Csaba SzepesváriConference on Neural Information Processing Systems (NeurIPS) 2023.
[arxiv]
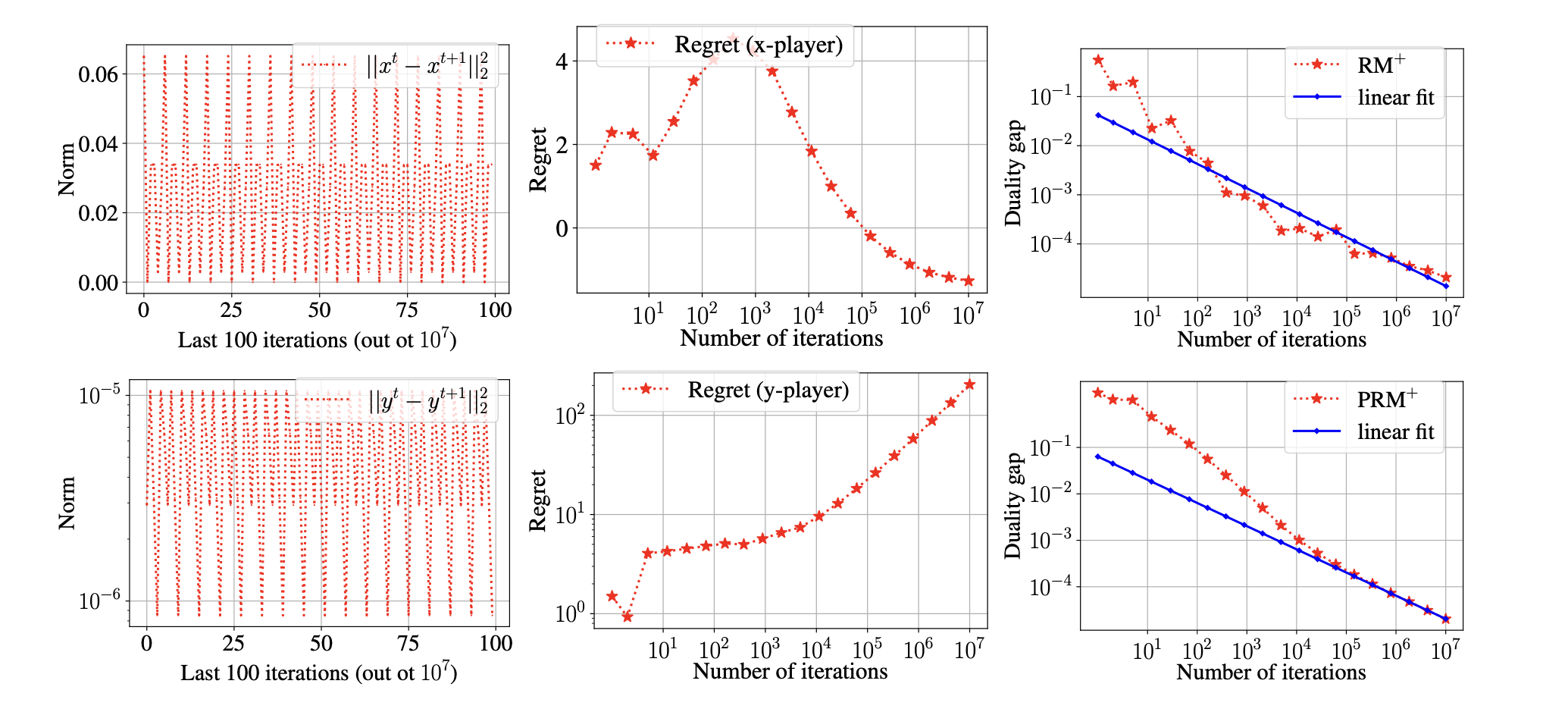
Regret Matching+: (In)Stability and Fast Convergence in Games
(α-β order) Gabriele Farina, Julien Grand-Clément, Christian Kroer, Chung-Wei Lee, Haipeng LuoConference on Neural Information Processing Systems (NeurIPS) 2023. (Spotlight)
[arxiv]
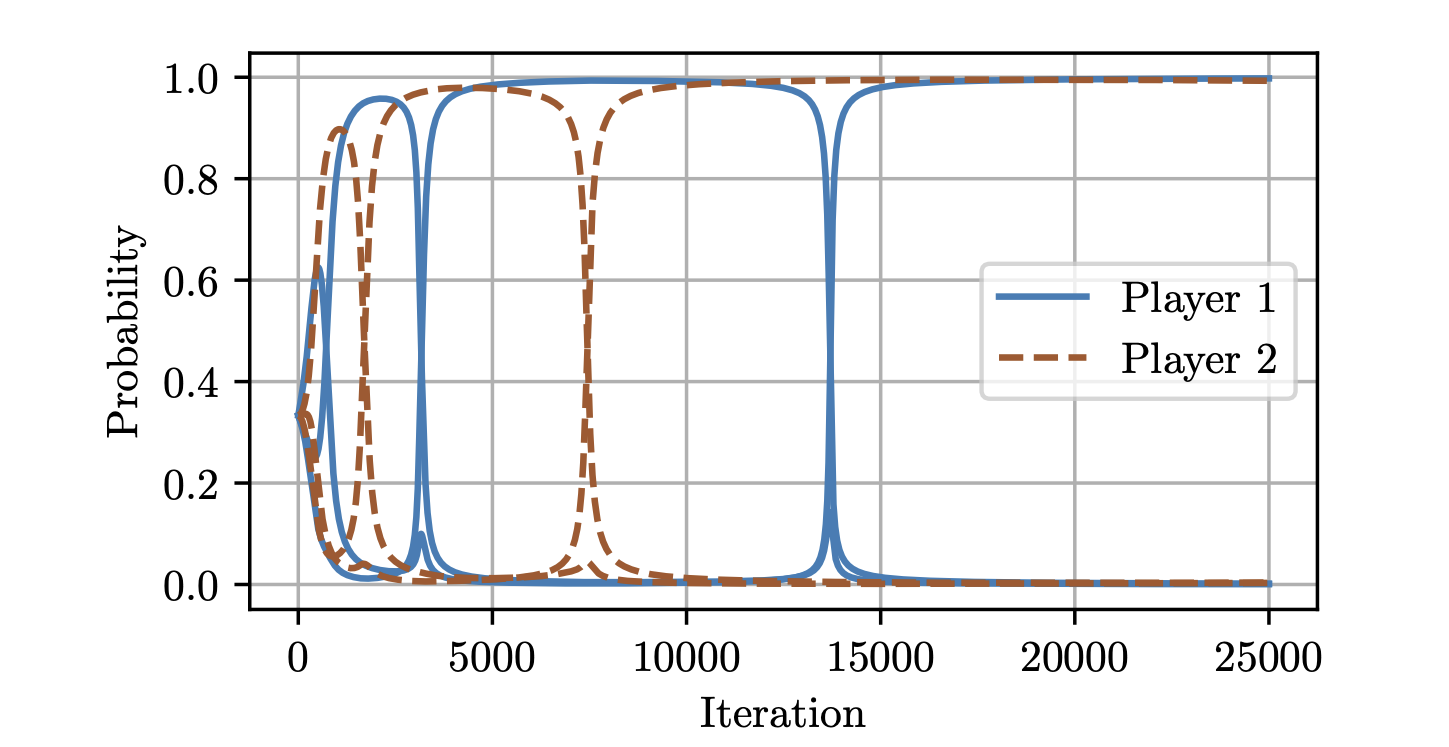
Uncoupled Learning Dynamics with O(log T) Swap Regret in Multiplayer Games
(α-β order) Ioannis Anagnostides, Gabriele Farina, Christian Kroer, Chung-Wei Lee, Haipeng Luo, Tuomas SandholmConference on Neural Information Processing Systems (NeurIPS) 2022. (Oral)
[arxiv]

Near-Optimal No-Regret Learning Dynamics for General Convex Games
Gabriele Farina, Ioannis Anagnostides, Haipeng Luo, Chung-Wei Lee, Christian Kroer, Tuomas SandholmConference on Neural Information Processing Systems (NeurIPS) 2022.
[arxiv]
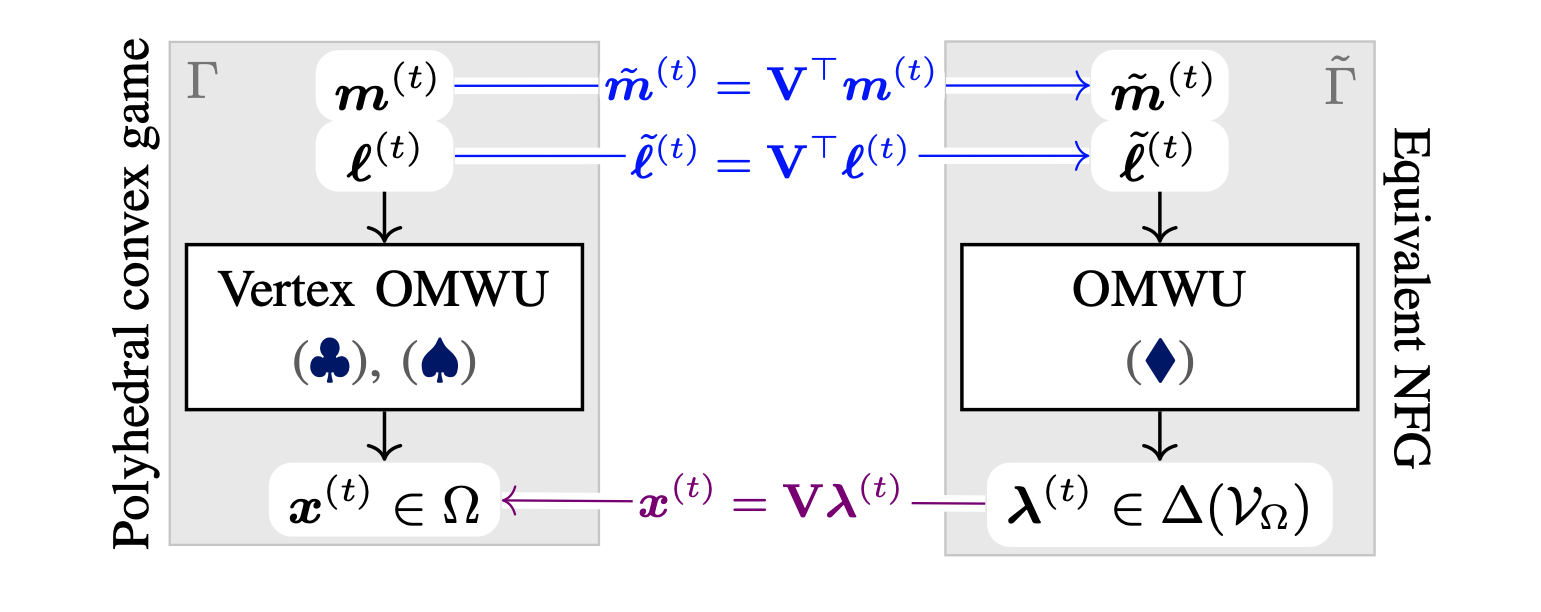
Kernelized Multiplicative Weights for 0/1-Polyhedral Games: Bridging the Gap Between Learning in Extensive-Form and Normal-Form Games
Gabriele Farina, Chung-Wei Lee, Haipeng Luo, Christian KroerInternational Conference on Machine Learning (ICML) 2022.
[arxiv]
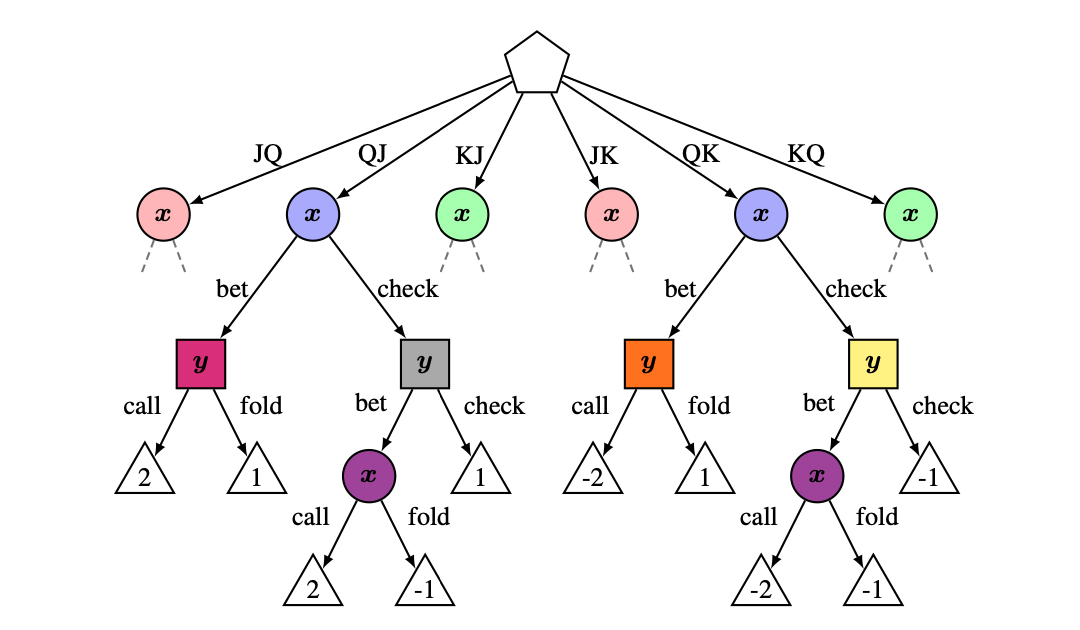
Last-iterate Convergence in Extensive-form Games
Chung-Wei Lee, Christian Kroer, Haipeng LuoConference on Neural Information Processing Systems (NeurIPS) 2021.
[arxiv]
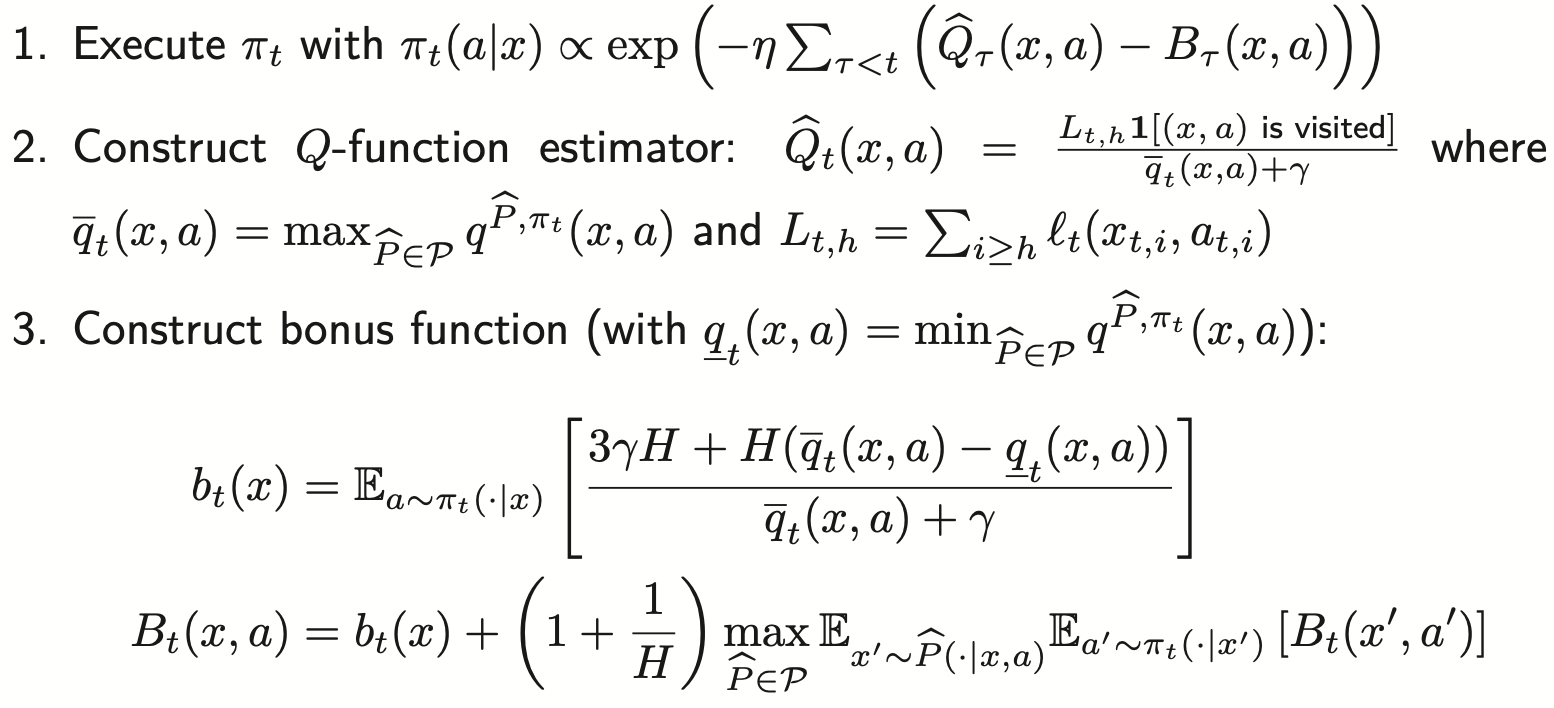
Policy Optimization in Adversarial MDPs: Improved Exploration via Dilated Bonuses
Haipeng Luo, Chen-Yu Wei, Chung-Wei LeeConference on Neural Information Processing Systems (NeurIPS) 2021.
[arxiv]
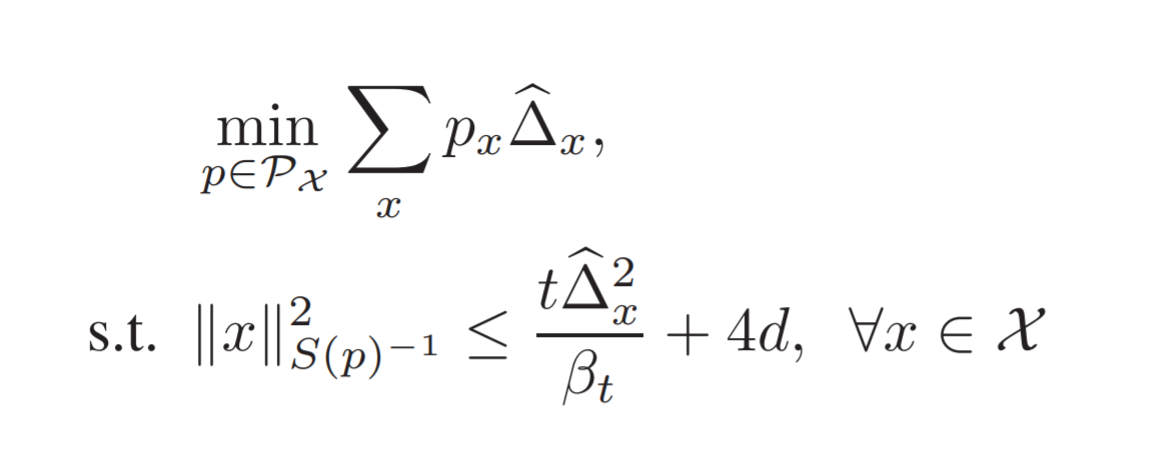
Achieving Near Instance-Optimality and Minimax-Optimality in Stochastic and Adversarial Linear Bandits Simultaneously
(α-β order) Chung-Wei Lee, Haipeng Luo, Chen-Yu Wei, Mengxiao Zhang, Xiaojin ZhangInternational Conference on Machine Learning (ICML) 2021.
[arxiv]

Last-iterate Convergence of Decentralized Optimistic Gradient Descent/Ascent in Infinite-horizon Competitive Markov Games
Chen-Yu Wei, Chung-Wei Lee, Mengxiao Zhang, Haipeng LuoAnnual Conference on Learning Theory (COLT) 2021.
[arxiv]
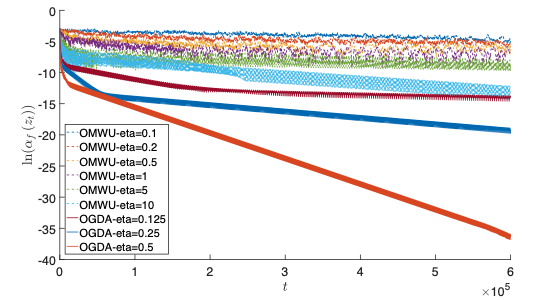
Linear Last-iterate Convergence in Constrained Saddle-point Optimization
Chen-Yu Wei, Chung-Wei Lee, Mengxiao Zhang, Haipeng LuoConference on Learning Representations (ICLR) 2021.
[arxiv]
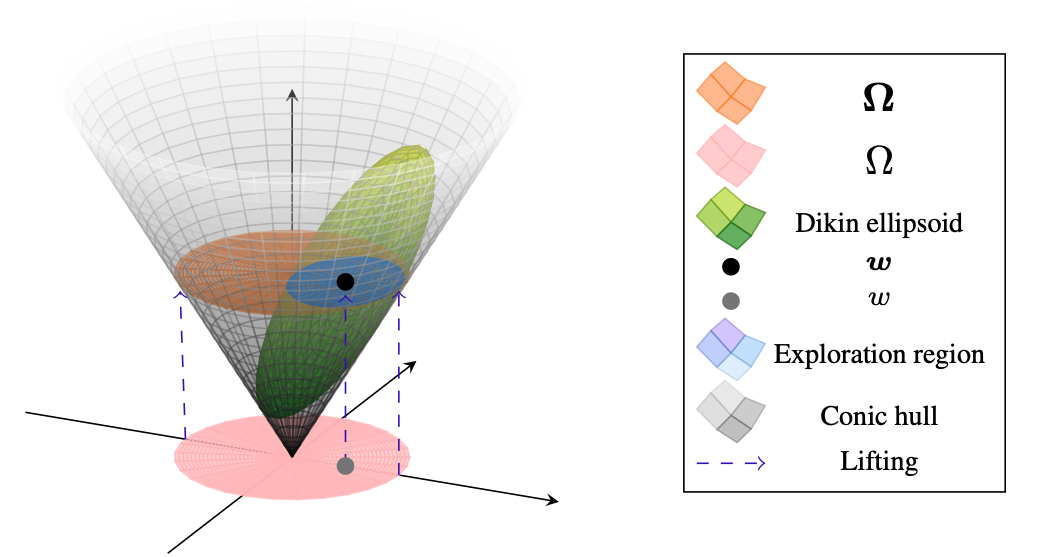
Bias No More: High-probability Data-dependent Regret Bounds for Adversarial Bandits and MDPs
(α-β order) Chung-Wei Lee, Haipeng Luo, Chen-Yu Wei, Mengxiao ZhangConference on Neural Information Processing Systems (NeurIPS) 2020. (Oral)
[arxiv]
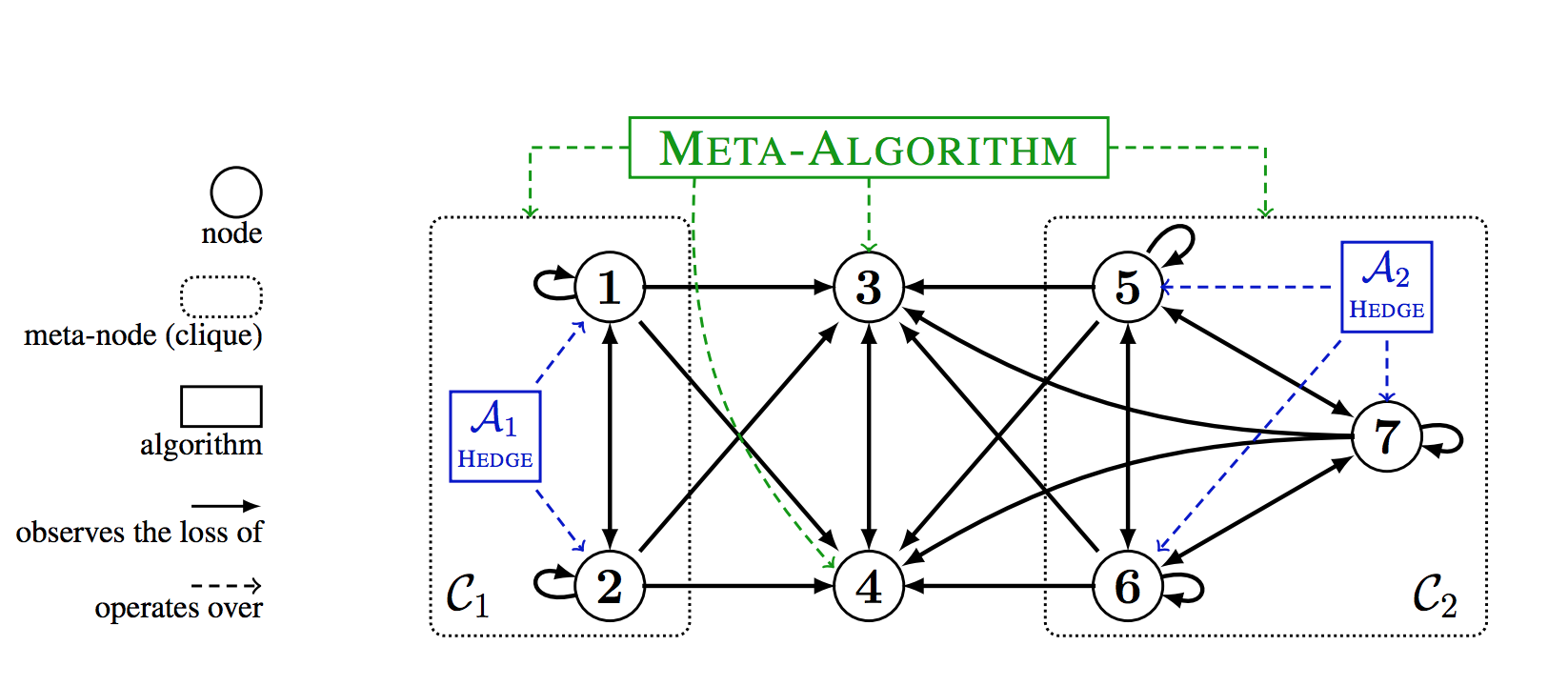
A Closer Look at Small-loss Bounds for Bandits with Graph Feedback
(α-β order) Chung-Wei Lee, Haipeng Luo, Mengxiao ZhangAnnual Conference on Learning Theory (COLT) 2020.
[arxiv]
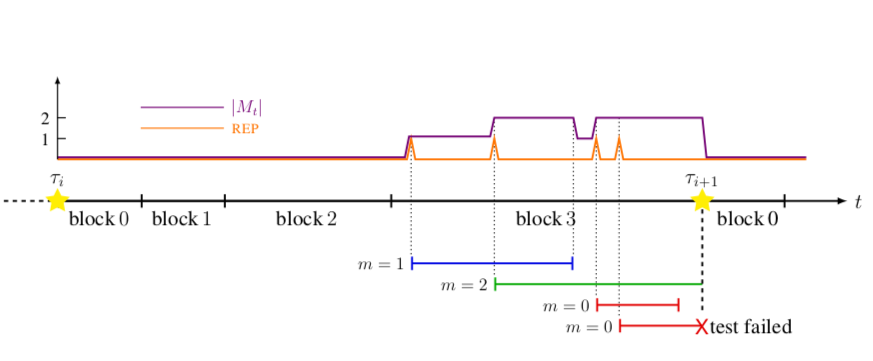
A New Algorithm for Non-stationary Contextual Bandits: Efficient, Optimal, and Parameter-free
(α-β order) Yifang Chen, Chung-Wei Lee, Haipeng Luo, Chen-Yu WeiAnnual Conference on Learning Theory (COLT) 2019.
[arxiv]
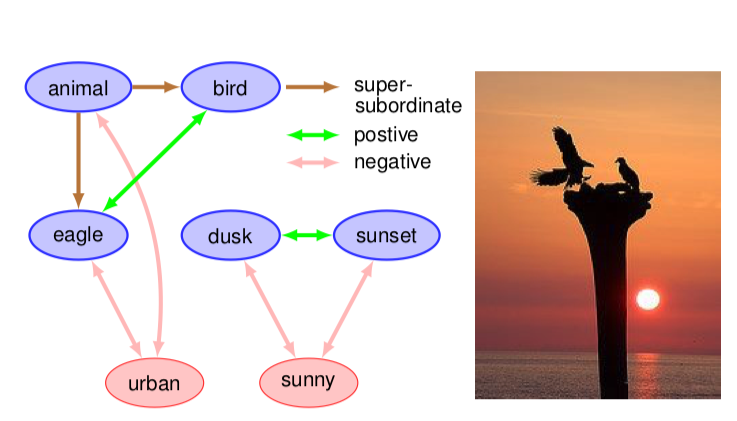
Multi-Label Zero-Shot Learning with Structured Knowledge Graphs
Chung-Wei Lee, Wei Fang, Chih-Kuan Yeh, Yu-Chiang Frank WangIEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2018.
[arxiv]
Preprints
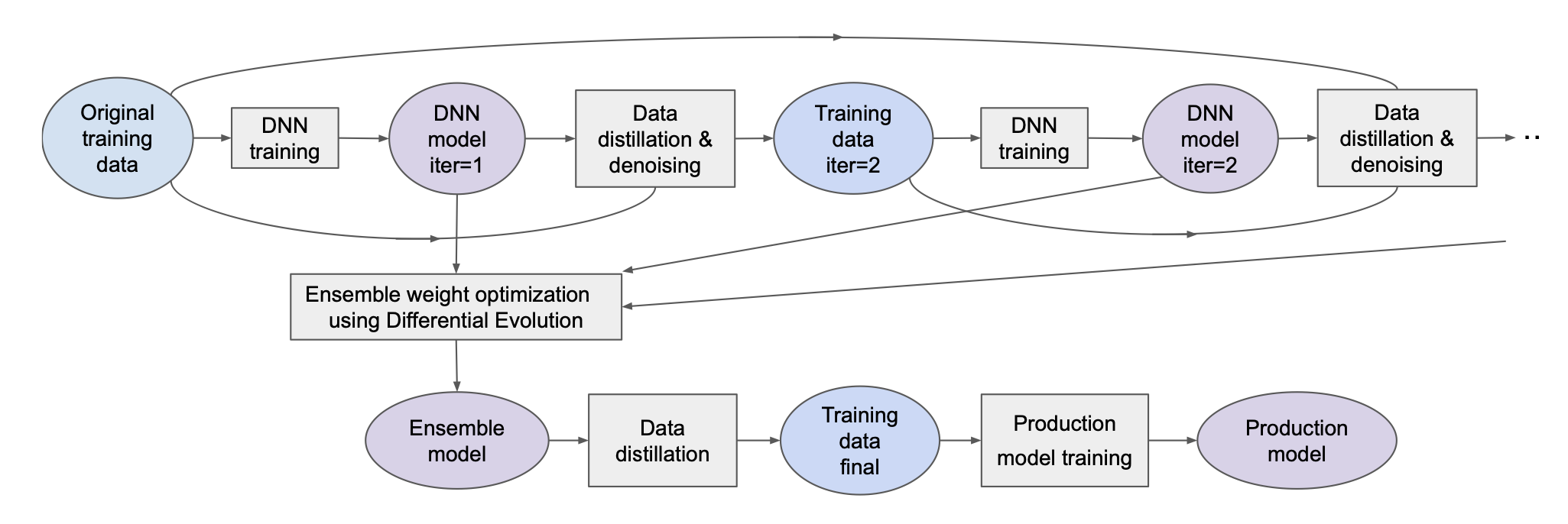
Practical Knowledge Distillation: Using DNNs to Beat DNNs
Chung-Wei Lee, Pavlos Athanasios Apostolopulos, Igor L. MarkovIntern project report.
[arxiv]